Cricket and financial markets have a rich, intertwined history, from
Vincent back to
Waugh/Warne,
Lillee/Marsh and
Keith Miller. So, I don't think we necessarily need a new cricket market, but let's make one anyway, and refresh my financial maths and linear algebra at the same time.
Cricket, especially its shortened forms, is seemingly becoming a batsman's game. Bats are bigger, fields are smaller, fielding and bowling restrictions make it difficult to pressure the batsmen, players are fitter and the game is more professional than it has ever been. The trend towards bigger scores is shown clearly in men's One-day International (ODI) cricket. The following chart shows the yearly average score each team scored when batting first in an ODI
*, with the black line (ODIAll) being the average of all games in that year. The "Associate" line refers to
Associate cricket teams that played games the International Cricket Council (ICC) deemed worthy enough to have ODI status, and also those World XI, Asia XI and Africa XI matches that were in vogue about 10 years ago and were also given ODI status. Individual Associate nations did not play enough games to create enough meaningful data for this analysis.
*Only innings that went for 50-overs, or where the team was bowled out, were counted so as to take out the influence of rain.
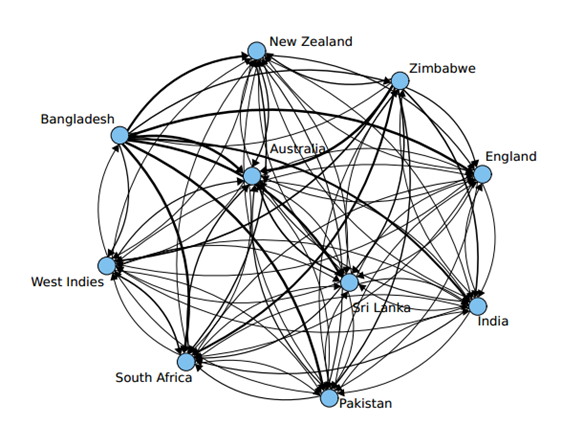
In our financial market, each of the series above is a stock, whose value is that team's average ODI score batting first in that year. The ODIAll series is the
index for this particular stock market (like the
S&P 500 or
All Ordinaries). The upward trend in ODIAll is clear, and the following shows ODIAll data with an exponential fit. An exponential fit is what you would expect if the stock was growing with continuously compounding interest. The fit is pretty good (R
2 = 0.8). The other dots are the country data and show the scatter (and noise) in the data set. I've gone back to 1980, as before then there were few games played annually.

Such trends are evident in other sports, but not all sports are as focused on increasing scores.
Premier League football shows no such scoring trend,
total home runs in Major League Baseball ebbs and flows depending on a number of factors including the
amount of steroids being taken, but there has been a
steady increase in strike outs over the last 20 years.
Let's do some maths. What we want to do is determine in which teams we should invest. We don't necessarily want to invest in the teams that regularly produce the highest scores. We want to pick the teams that are improving - that is, their stock prices are going up so we'll get a good return. For instance, Australia has been dominant in ODI cricket for some time; it may not be a good investment if it can not continue to grow its already large yearly average. On the other hand, Associate teams are playing more ODI cricket and Bangladesh is ever improving, perhaps they would be better investments, although likely to be more risky than an established team. Maybe we'd be better off just buying the ODIAll Index.
Inline with
Modern Portfolio Theory, I used the methods in these two articles:
Yes, I did it in Excel, and yes I realise that if I was any sort of data analyst I would have done it in
R, but if you can't go 80% of the way towards solving the problem in Excel, it's not a problem worth solving.
The following chart shows the average percentage return and standard deviation of each country's yearly stock price. On average, Australia increases its price by ~1%, with a standard deviation (risk) of 8%. Interestingly, South Africa, for a similar risk, has a ~2% return. Bangladesh is the
BRIC of this market, rapidly improving over the last few years, but with a relatively high risk. The Associates are far too risky to invest in just yet.

To determine your portfolio, you don't just need the risk/return values,
but we also need to know whether an increase in one country's stock
will cause an increase (or decrease) in another. This is measured by
covariance.
In our case, the prices of all countries are generally moving upwards
over time, however there are some interesting pairs of countries that
move together in the same direction (Sri Lanka and New Zealand) and in
the opposite direction (Zimbabwe and Bangladesh). I suspect a lot of
this is noise. In any case, by knowing that an increase in one stock
price will likely see a decrease in another, you can minimise the
overall risk of your portfolio by hedging.
To determine which teams we should include in our portfolio, we need to determine the
Efficient Frontier. This is the line on which you can not get a higher return from any combination of assets in your portfolio for your choice of risk. For example, if you are happy to take on a risk of 20%, you can't expect a return more than 8% from these assets - yes, it's not exactly the sort of market I'd want to buy into, but let's keep going...
The next thing we need is the
Capital Market Line (CML). In any market, there may be what is known as a "
risk-free asset" - an asset which gives a guaranteed return with no risk. In financial modelling, government bonds assume the role of risk-free asset, as they have a known return and as the government has almost zero chance of default, are assumed risk-free. The CML is the line drawn from the point of the risk-free asset (on the y-axis) such that it is tangent to the efficient frontier. The intercept point is known as the
market portfolio. Along the CML, your portfolio contains various amounts of the risk-free asset and the market portfolio (the risky asset).
There is no real equivalent to a risk-free asset in this market, so I've assumed it to be 0.5%, which is, at time of writing, about the price of a
German 10-year government bond (this market is based in Germany, for no particularly good reason. Perhaps a German financier, tired of his team being
ranked between Gibraltar and the Isle of Man, wanted some fun).
The market portfolio allows you to
short sell; that is, sell stock you don't currently own. Perhaps you've borrowed it and sold it on. But you have to buy it back to give it back to the person from whom you borrowed it. You'd do this if you were expecting the price to drop so you would be buying it back at a lower price than you sold it, or as in our scenario, as a hedge. You can also determine the optimal portfolio if short-selling is not allowed, and the minimum risk portfolio. The weightings are below. Essentially, if you don't mind a bit of risk, buy Bangladesh and South Africa. If you want a bit more safety, replace Bangladesh with Australia.
|
Market Portfolio |
No short selling |
Minimum Risk Portfolio |
| Australia |
-0.09 |
0.01 |
0.26 |
| England |
-0.18 |
0.00 |
0.00 |
| New Zealand |
0.10 |
0.06 |
0.00 |
| India |
0.03 |
0.00 |
0.10 |
| Pakistan |
0.11 |
0.05 |
0.07 |
| West Indies |
0.00 |
0.00 |
0.09 |
| South Africa |
0.44 |
0.35 |
0.23 |
| Sri Lanka |
-0.04 |
0.00 |
0.07 |
| Zimbabwe |
0.20 |
0.16 |
0.09 |
| Bangladesh |
0.42 |
0.36 |
0.09 |
| Associate |
0.00 |
0.01 |
0.00 |
How are these portfolios going in 2016 (at Feb 14)? Well, noting that some of the teams have yet to play this year (so I have assumed they have a 0% return), if you'd bought the ODIAll index, you'd be up 7%, the minimum risk portfolio is down 0.9%, the no-short-selling portfolio is down 7.6% and the market portfolio is down 13.1%. This is inline with the amount of risk in each portfolio, but not a good result. Still, the year is young.
Would I ever use this technique to develop a portfolio for such a market? I don't think so. This method weights a team's return from 1981 to 1982 the same as the 2009 to 2010 return. In cricket, I suspect you need to look recent form as opposed to historic, and be more specific with regards who each team is playing, and where. There's probably not enough data for the correlations and covariances to really mean anything either.
Can the ODIAll Index continue to increase? This market is much like a real financial market - you can not expand forever in a world of limited resources. It has to come to an end at some point. There are ways, however, that teams could attempt to increase their own prices in the short-term. Australia, which has traditionally been very poor at playing nations it doesn't deem good enough to take the field with, could actually start to play some games against Bangladesh, Zimbabwe and the Associates; the financial markets analogy would be a company outsourcing its manufacturing to countries where they don't pay their workers well. This approach would not necessarily work for teams like India and Sri Lanka, who have been plundering week bowling attacks and bolstering their averages for some time. But at least they are attempting to grow the game, perhaps cognisant of the fact that for long periods of time they were also not particularly good (some Australia, as a foundation Test nation, never really had to think about). It will be interesting to see if India continues to do this as they
take over the ICC.
The Big 3 would do well to remember that they are big because of the international market and that it should be nurtured. To the (previous)-ICC's credit, the international ODI market has liberalised since around 2005, with more countries playing games with ODI status. However, it remains to be seen whether you'll ever be able to buy stock in individual Associate nations in our market.
Many things could influence this market in the future. How regulated is it going to become? Will the number of nations playing ODIs grow or shrink? Where will technology trend, what rule changes are going to come in? Or will ODI cricket die in the face of T20 cricket?








.JPG)



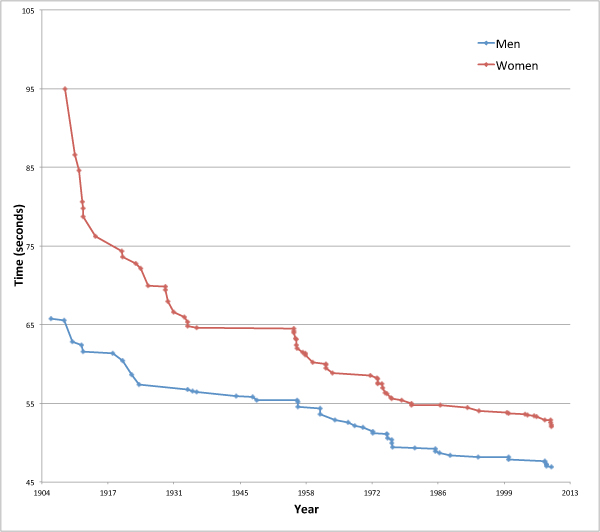
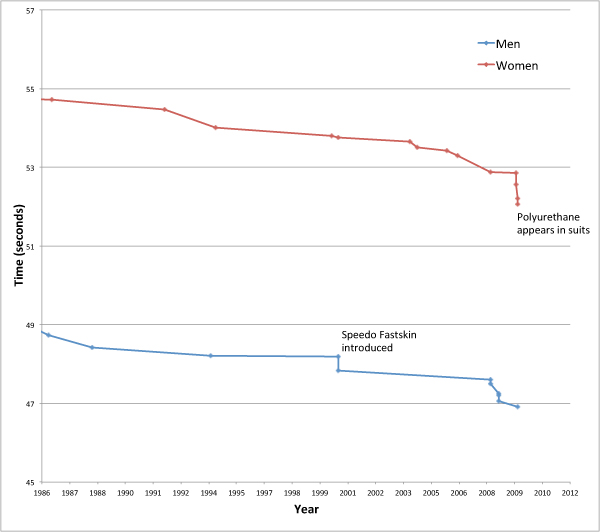
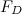 of the drag force acting on a swimmer moving in a fluid is given by the following equation
of the drag force acting on a swimmer moving in a fluid is given by the following equation![\[ F_ D=\frac{1}{2}\rho v^2 C_ D A, \]](http://plus.maths.org/MI/1090f42a51914e0ebd03b208305002ac/images/img-0002.png)
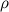 is the mass density of the fluid
is the mass density of the fluid is the speed of the swimmer relative to the fluid
is the speed of the swimmer relative to the fluid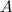 is the swimmer's cross-sectional area, that is the area of your body as it is pushing through the water head on
is the swimmer's cross-sectional area, that is the area of your body as it is pushing through the water head on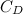 is the drag-coefficient,
a number which depends on factors such as the exact shape of the
swimmer and the hydrodynamic qualities of their skin and what they are
wearing.
is the drag-coefficient,
a number which depends on factors such as the exact shape of the
swimmer and the hydrodynamic qualities of their skin and what they are
wearing.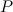 is
the rate at which your body uses its energy, and when you are swimming
the power you exert is proportional to the cube of your speed
is
the rate at which your body uses its energy, and when you are swimming
the power you exert is proportional to the cube of your speed 
![\[ P=F_ D v = \frac{1}{2}\rho C_ D A v^3. \]](http://plus.maths.org/MI/caa263a0adba65e63c48c3c9203b58b5/images/img-0003.png)
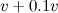 . To do this solely by increasing your power, you need to exert a new power
. To do this solely by increasing your power, you need to exert a new power 
![\[ P_1 = \frac{1}{2}\rho C_ D A (v+0.1v)^3. \]](http://plus.maths.org/MI/caa263a0adba65e63c48c3c9203b58b5/images/img-0006.png)
![\[ Increase = 100 \times \frac{P_1-P}{P}= 100 \times (\frac{P_1}{P}-1). \]](http://plus.maths.org/MI/caa263a0adba65e63c48c3c9203b58b5/images/img-0007.png)
![\[ \frac{P_1}{P} = \frac{\frac{1}{2}\rho C_ D A (v+0.1v)^3}{\frac{1}{2}\rho C_ D A v^3}=(1.1)^3=1.331 \]](http://plus.maths.org/MI/caa263a0adba65e63c48c3c9203b58b5/images/img-0008.png)
![\[ Increase =100 \times (1.331-1)\% =33.1\% . \]](http://plus.maths.org/MI/caa263a0adba65e63c48c3c9203b58b5/images/img-0009.png)
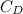 is
is![\[ C_ D=\frac{2P}{\rho A v^3}. \]](http://plus.maths.org/MI/caa263a0adba65e63c48c3c9203b58b5/images/img-0011.png)
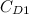 of
of![\[ C_{D1}=\frac{2P}{\rho A (v+0.1v)^3}. \]](http://plus.maths.org/MI/caa263a0adba65e63c48c3c9203b58b5/images/img-0013.png)
![\[ Decrease = 100 \times \frac{C_ D-C_{D1}}{C_ D}=100 \times (1-\frac{C_{D1}}{C_ D}) = 100 \times (1-\frac{1}{1.1^3})= 25\% . \]](http://plus.maths.org/MI/caa263a0adba65e63c48c3c9203b58b5/images/img-0014.png)